
이번 주제에서 다루어 볼 것은 후위 표기법입니다. 후위 표기법은 스택을 활용하여 산술연산을 용이하게 도와주는 알고리즘 중 하나입니다.
후위 표기법이란?
표기법에는 표기식의 위치에 따라 전위 표기법, 중위 표기법, 후위 표기법이 있습니다. 전위, 중위, 후위는 연산자의 위치에 따라 달리 부릅니다. 우리가 일상에서 가장 익숙한 것은 중위 표기법입니다. 가령, A와 B를 더하는 산술 표기를 중위 표기법으로 나타내면 A+B입니다. 이것은 전위로 나타내면 +AB가 되며, 후위로 나타내면 AB+가 됩니다. 이때 +, -, *, / 를 연산자(operator)라고 하고 연산의 대상이 되는 A, B와 같은 연상 대상을 피연산자(operand)라고 합니다.
중위로 표기된 식을 전위 표기법, 후위 표기법으로 변환하는 방법은 각각 다음과 같습니다.
전위 표기법
중위 표기법을 전위 표기법으로 변환하는 방법은 다음과 같습니다.
- 수식을 연산자와 피연산자로 나눕니다. 괄호 등으로 표시를 하면 직관적으로 보기 쉽습니다.
- 전위 표기이기에 연산자를 앞쪽으로 이동합니다.
예를 들면 5+2*3인 경우 다음과 같습니다.
- 연산 순서에 따라 괄호로 표시해보겠습니다. => (5+(2*3))
- 연산자를 왼쪽으로 이동합니다. => +5*23
- 연산자가 앞에 있기에 계산은 우측에서 시작합니다. 3과 2를 곱하고 5를 더합니다.
후위 표기법
중위 표기법을 후위 표기법으로 하는 변환하는 방법은 전위와 반대로 하면 됩니다.
5+2*3을 예로 들면 연산자가 후위로 이동하기에 다음과 같습니다.
- 괄호로 묶어보겠습니다. => (5+(2*3))
- 연산 순서가 2*3이 최우선이므로 후위 표기하면 23*이 됩니다. => (5+(23*))
- (5+(23*)) 에서 23*을 한 묶음이므로 + 연산자를 후위로 하면 523*+가 됩니다.
후위 표기법 변환 스택으로 하기
후위 표기법을 왜 쓰는 것일까요? 예를 들면 백분율의 증가 및 감소를 생각해 봅시다. 우선 중위 표기로 백분율 증감을 표시하면 다음과 같을 것입니다.
- (V1 - V0) / V0
- V0가 이전값, V1이 이후값으로 가정합니다.
근데 1번 고객이 보는 자료의 코드는 V0, V1, W0, W1가 있고, 2번 고객의 코드는 X0, X1, Y0, Y1이 있다고 가정해 봅시다. 1번은 "V만 증감률을 표시해 주세요", 2번은 "X와 Y의 증감률을 각각 모두 표시해 주세요"와 같은 요구사항이 있을 때 어떻게 해야 할까요? 또한 3번 고객은 V1 코드가 이전값이고 V0가 이후값이어서 증감률 계산이 (V0 - V1) / V1이 되어야 한다면? V0를 이전값으로 프로그래밍해 놓았다면 "증감률이 이상하게 나와요"라는 3번 고객의 하소연을 들을지도 모릅니다.
이때, 요청사항에 따라 각각의 코드를 보여주도록 프로그램을 하드코딩하는 방법이 있을 것입니다. 분기문을 활용하여 각각의 고객에 맞추어 설정하는 방법은 쉽고 단순하지만, 추가적인 변경사항이 있을 때마다 프로그램을 계속 수정하여야 합니다.
하지만 고객이 원하는 값으로 유동적으로 계산할 수 있도록 관리할 수 있다면? 이때 후위 표기법이 도움이 될 것입니다. 물론 이러한 상황뿐만 아니라 여러 다양한 상황에서 활용 가능합니다.
중위 표기법은 컴퓨터가 계산하기 힘듭니다. 예를 들면 (a+(b-c)/d)+((e/f)+g*h) 식을 계산하라고 할 때, 사람은 (b-c)와 (e/f)를 가장 먼저 계산해야 한다는 걸 보고 알 수 있습니다. 하지만, 이를 프로그래밍으로 나타낼 때 두 수식을 먼저 계산하라는 것을 어떻게 표시해야 할지 막막합니다. 특히 식이 고정이 아니면 더욱더 말이죠.
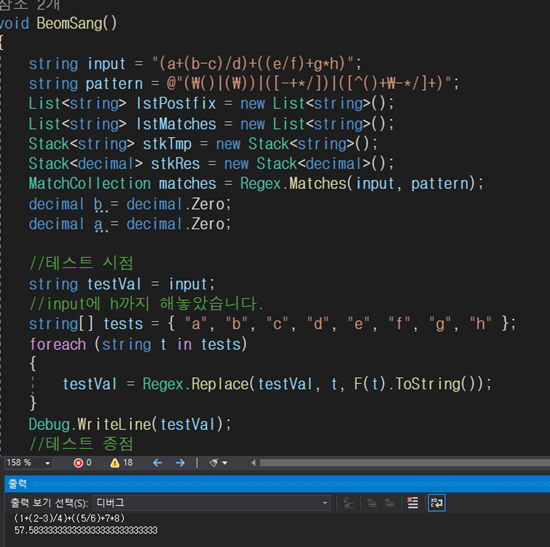
후위 표기법은 식을 스택으로 변환하여 순차적으로 계산할 수 있도록 지원합니다. 위의 식을 계산하는 방법 예제입니다.
후위 표기법 예제
- 예제 수식은 (a+(b-c)/d)+((e/f)+g*h)로 하겠습니다. 이를 활용하여 위의 예시에서 1번 고객은 (V1-V0)/V0를 구하고, 2번 고객은 (X1+Y1-(X0+Y0)) / (X0+Y0)를 구하고, 3번은 (V0-V1)/V1을 구할 수 있을 것입니다.
- 정규표현식을 사용하여 괄호 우선순위와 사칙연산, 그리고 그 외의 것을 구해보도록 하겠습니다. 저는 숫자뿐만 아니라 문자도 고려하도록 설계하였기에 이런 식으로 만들었습니다.
- 우선 정규표현식에서 입력된 값을 패턴에 맞추어 추출한 값을 리스트에 담도록 하겠습니다.
- 해당 리스트에 담은 변수는 임시로 만든 스택과 후위 표현식을 담고 있는 리스트에 각각 입력할 예정입니다. 해당 스택에 있는 값은 모두 팝 하여 리스트에 추가할 예정입니다.
- 그리고 마지막으로 후위 표기법으로 추가한 리스트를 순차적으로 읽으며 계산할 스택에 담습니다. 피연산자이면 스택에 담고, 그 외의 경우 스택을 2번 팝하여 반환한 피연산자를 해당 연산자로 연산한 결과를 다시 담습니다. 해당 동작을 반복하여 마지막 팝 한 결과를 얻습니다.
스택이란?
스택의 정의와 스택과 관련한 기초 함수 안내를 해드리겠습니다. 오류가 발생하였을 때, "호출스택(콜스택)을 참고하여 확인하라"는 말을 들어보셨을 겁니다. 스택은 차곡차곡 쌓아가는 자료구조를 의미하며 호출스택 또한 오류가 발생하기까지의 경위가 순차적으로 누적되어 쌓여있습니다. 그리하여 호출스택의 가장 윗부분이 오류가 발생하기 직전의 상황이며, 가장 아랫부분이 오류 발생의 시초가 되는 부분을 확인할 수 있습니다.
스택은 입력한 값이 계속 쌓이는 자료구조로, 값을 조회하면 가장 마지막 자료를 가져옵니다. 이를 후입선출(LIFO, Last-In-First-Out) 구조라고 합니다. 가장 뒤에 들어간 값이 가장 먼저 나온다는 뜻이지요. 이와 관련한 스택 함수 안내입니다.
- 푸시(PUSH) : 푸시는 밀다, 밀어넣다는 의미로 사용하죠? 푸시는 스택 자료구조에 값을 입력하는 함수입니다. SET과 비슷한 개념으로 볼 수 있습니다.
- 팝(POP) : 팝은 나오다, 터지다, 꺼내다의 뜻으로 사용하죠? 팝은 스택 자료구조에서 값을 가져오는 역할을 합니다. GET과 비슷한 개념으로 볼 수 있습니다. 물론, 후입선출에 따라 가장 마지막에 푸시한 값을 가져옵니다.
- 픽(PEEK) : 픽은 훔쳐보거나 살짝 엿보는 것을 뜻합니다. 팝과 마찬가지로 자료구조를 조회하는 함수이며, 가장 큰 특징은 픽을 하더라도 스택의 구조는 기존과 동일하다는 것입니다.
- 푸시와 팝 : 자료 구조의 핵심은 푸시와 팝입니다. 픽보다는 팝이 더 중요하니 푸시/팝을 기억해 주세요.
- 팝과 픽 : 팝은 꺼낸다는 뜻이라고 하였습니다. 그리고 픽은 단순히 조회해 보는 것입니다. 팝을 실행하면 자료가 아웃이 되기에, 스택 자료구조의 카운트가 감소합니다. 반면 픽은 자료를 추출하는 것이 아니라 조회만 하기에 카운트에는 변함이 없습니다.
그리하여 팝을 무한히 반복하면 자료구조의 카운트가 점점 감소하다가 스택이 비어있을 때 System.InvalidOperationException 예외가 발생합니다.
반면, 픽은 자료구조의 스택이 비어있지 않다면 무한히 반복하여도 예외는 발생하지 않습니다. 물론 비어있는 스택을 픽하면 팝과 동일하게 예외가 발생하기는 합니다.
후위 표기법 예제 소스
상기의 후위 표기법 예제에서 안내해드린 흐름입니다.
- 표현식에서 토큰을 추출합니다.
- 토큰이 피연산자인 경우 후위 표기법 리스트에 담습니다.
- 토큰이 좌괄호 ( 가 나오면 임시 스택에 담습니다.
- 토큰이 우괄호 ) 가 나오면 좌괄호 ( 가 나올 때까지 후위 표기법 리스트에 담습니다. 그리고 좌괄호를 버립니다.
- 토큰이 연산자이면, 임시 스택의 연산자와 우선순위를 비교하여, 높은 경우 후위 표기법에 담고 낮은 경우 임시 스택에 담습니다.
- 토큰을 모두 조회해 본 다음, 이제 나머지를 임시 스택에 있는 값을 후위 표기법 리스트에 추가해 줍니다.
- 그리고 마지막으로 후위 표기법 리스트에 있는 토큰을 조회하며, 순차적으로 계산을 진행합니다.
- 토큰이 피연산자이면 결과스택에 담습니다.
- 토큰이 연산자이면 결과 스택 0번 자료와 1번 자료에 피연산자가 있을 것입니다. 후입선출이므로, 0번 자료가 중위 표기법의 2번에 오는 피연산자, 1번 자료가 중위 표기법의 1번에 오는 피연산자입니다. 두 값을 팝 하여 토큰으로 연산합니다. 그리고 해당 값을 결과스택에 담습니다.
- 이를 스택이 1개가 남을 때까지 반복합니다. 토큰이 연산자일 때 팝을 2번 하고 푸시를 1번 하기 때문에 카운트가 1씩 감소하기 때문입니다. 후위 표기는 연산자가 후위로 간다고 했던 걸 기억하실 겁니다. 마지막 토큰(연산자)을 끝으로 스택에 하나의 값이 남습니다.
- 마지막으로 스택에 남아있는 1개의 값을 팝 하여 결과를 가져옵니다.
void BeomSang()
{
string input = "(a+(b-c)/d)+((e/f)+g*h)";
string pattern = @"(\()|(\))|([-+*/])|([^()+\-*/]+)";
List<string> lstPostfix = new List<string>();
List<string> lstMatches = new List<string>();
Stack<string> stkTmp = new Stack<string>();
Stack<decimal> stkRes = new Stack<decimal>();
decimal b = decimal.Zero;
decimal a = decimal.Zero;
MatchCollection matches = Regex.Matches(input, pattern);
//테스트 시점
string testVal = input;
//input에 h까지 해놓았습니다.
string[] tests = { "a", "b", "c", "d", "e", "f", "g", "h" };
foreach (string t in tests)
{
testVal = Regex.Replace(testVal, t, F(t).ToString());
}
Debug.WriteLine(testVal);
//테스트 종점
foreach (Match match in matches)
{
lstMatches.Add(match.Value);
}
foreach (string token in lstMatches)
{
if (Regex.IsMatch(token, @"[^()+\-*/]+"))
{
lstPostfix.Add(token);
}
else if (token == "(")
{
stkTmp.Push(token);
}
else if (token == ")")
{
while (stkTmp.Peek() != "(")
{
lstPostfix.Add(stkTmp.Pop());
}
stkTmp.Pop();
}
else
{
while (stkTmp.Count != 0)
{
if (GetPrecedence(stkTmp.Peek()) >= GetPrecedence(token))
{
lstPostfix.Add(stkTmp.Pop());
}
else
{
break;
}
}
stkTmp.Push(token);
}
}
while (stkTmp.Count > 0)
{
lstPostfix.Add(stkTmp.Pop());
}
foreach (string token in lstPostfix)
{
if (Regex.IsMatch(token, @"[^+\-*/]+"))
{
stkRes.Push(Convert.ToDecimal(F(token)));
}
else
{
b = stkRes.Pop();
a = stkRes.Pop();
switch (token)
{
case "+":
stkRes.Push(a + b);
break;
case "-":
stkRes.Push(a - b);
break;
case "*":
stkRes.Push(a * b);
break;
case "/":
stkRes.Push(a / b);
break;
}
}
}
Debug.WriteLine(stkRes.Pop());
}
static int GetPrecedence(string oper)
{
switch (oper)
{
case "+":
case "-":
return 1;
case "*":
case "/":
return 2;
default:
return -1;
}
}
static string F(string s)
{
switch (s)
{
case "a":
return "1";
case "b":
return "2";
case "c":
return "3";
case "d":
return "4";
case "e":
return "5";
case "f":
return "6";
case "g":
return "7";
case "h":
return "8";
default:
return string.Empty;
}
}